Amazon Data Firehose представляет новую функцию, которая фиксирует изменения в базах данных, таких как PostgreSQL и MySQL, и передает обновления в таблицы Apache Iceberg в Amazon S3. Это обеспечивает простое комплексное решение для потоковой передачи обновлений базы данных без ущерба для производительности транзакций. Пользователи могут настроить поток Data Firehose за считанные минуты для доставки обновлений CDC (Change Data Capture) из своих баз данных. Теперь они могут легко реплицировать данные из различных баз данных в таблицы Iceberg в Amazon S3 и использовать актуальные данные для крупномасштабной аналитики и приложений машинного обучения (ML). Корпоративные клиенты AWS обычно используют сотни баз данных для транзакционных приложений. Чтобы выполнять крупномасштабную аналитику и машинное обучение на основе последних данных, им необходимо фиксировать изменения, внесенные в базы данных, например, когда записи в таблице вставляются, изменяются или удаляются, и доставлять обновления в свое хранилище данных или озеро данных Amazon S3 в форматах таблиц с открытым исходным кодом, таких как Apache Iceberg. Многие клиенты разрабатывают задания ETL (извлечение, преобразование, загрузка) для периодического чтения из баз данных. Однако средства чтения ETL влияют на производительность транзакций базы данных, а пакетные задания могут добавить несколько часов задержки, прежде чем данные станут доступны для аналитики. Чтобы смягчить это воздействие, клиенты хотят передавать изменения, внесенные в базу данных, в потоковом режиме, что называется потоком CDC. Благодаря этой новой функции потоковой передачи данных Data Firehose добавляет возможность получать и непрерывно реплицировать потоки CDC из баз данных в таблицы Apache Iceberg в Amazon S3. Пользователи настраивают поток Data Firehose, указывая источник и назначение. Data Firehose фиксирует и реплицирует начальный снимок данных, а затем все последующие изменения в выбранных таблицах базы данных в виде потока данных. Для получения потоков CDC Data Firehose использует журнал репликации базы данных, что снижает влияние на производительность транзакций базы данных. Когда объем обновлений базы данных колеблется, Data Firehose автоматически разбивает данные на разделы и сохраняет записи до их доставки. Пользователям не нужно выделять ресурсы или управлять кластерами. Data Firehose также может автоматически создавать таблицы Apache Iceberg, используя ту же схему, что и таблицы базы данных, во время первоначального создания потока, и автоматически развивать целевую схему на основе изменений исходной схемы. Являясь полностью управляемым сервисом, Data Firehose устраняет необходимость в компонентах с открытым исходным кодом, обновлениях программного обеспечения и эксплуатационных расходах.
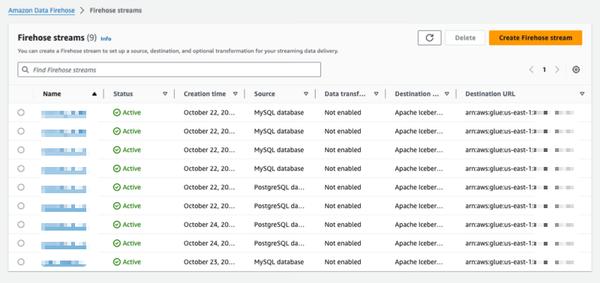
Репликация изменений из баз данных в таблицы Apache Iceberg с помощью Amazon Data Firehose (в предварительной версии)
AWS