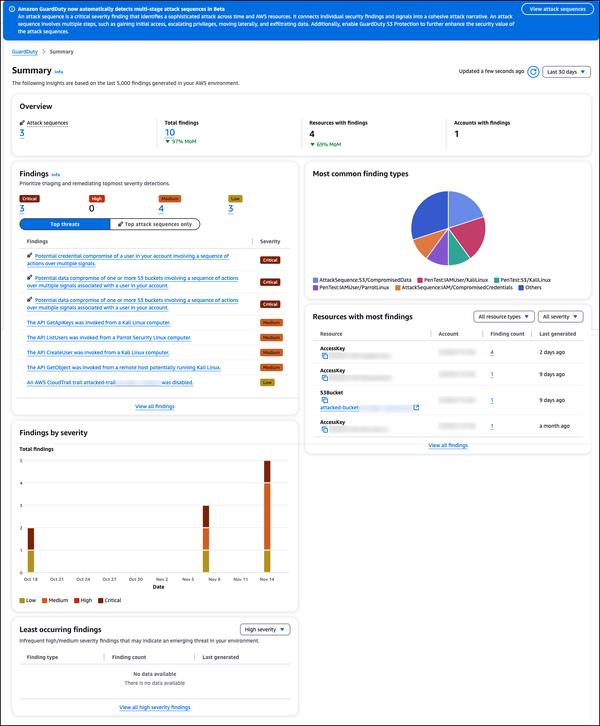
Google Cloud опубликовала запись в блоге на тему «Экономьте на GPU: более интеллектуальное автомасштабирование для ваших рабочих нагрузок GKE». В статье рассказывается о том, что запуск рабочих нагрузок вывода модели LLM может быть дорогостоящим, даже при использовании новейших открытых моделей и инфраструктуры.
Одним из предлагаемых решений является автомасштабирование, которое помогает оптимизировать расходы, гарантируя, что вы удовлетворяете потребности клиентов, оплачивая только те ускорители ИИ, которые вам нужны.
В статье представлены рекомендации по настройке автомасштабирования для рабочих нагрузок вывода в GKE, с упором на выбор правильной метрики.
Мне было особенно интересно сравнить различные метрики для автомасштабирования на GPU, такие как использование GPU, размер пакета и размер очереди.
Я обнаружил, что использование GPU не является эффективной метрикой для автомасштабирования рабочих нагрузок LLM, поскольку это может привести к избыточному выделению ресурсов. С другой стороны, размер пакета и размер очереди являются прямыми показателями объема трафика, с которым сталкивается сервер вывода, что делает их более эффективными метриками.
В целом, в статье представлен полезный обзор того, как оптимизировать соотношение цены и производительности рабочих нагрузок вывода LLM в GKE. Рекомендую эту статью всем, кто планирует развертывать рабочие нагрузки вывода LLM в GKE.