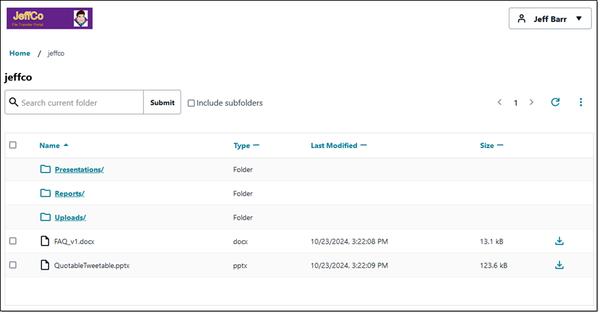
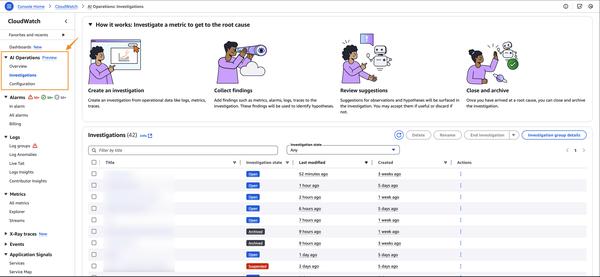
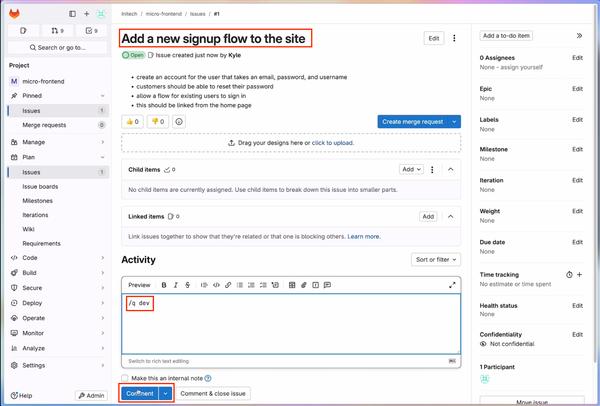
Google Cloud выпустила демонстрационную версию решения для мультимодального поиска, позволяющего выполнять поиск по изображениям и видео с помощью текстовых запросов. Это решение использует модели мультимодального встраивания для понимания семантического содержания изображений и видео, что обеспечивает более точный и полный поиск.
Эта демонстрация особенно меня воодушевляет своим потенциалом в различных областях. Представьте, например, что вы можете искать в обширной базе данных медицинских изображений, используя текстовые описания симптомов или аномалий. Это может дать возможность медицинским работникам ставить диагнозы быстрее и точнее.
Кроме того, это решение может революционизировать то, как мы взаимодействуем с онлайн-контентом. Вместо того чтобы полагаться исключительно на ключевые слова, мы могли бы выполнять поиск, используя комбинацию текста, изображений и видео, что сделало бы поиск более интуитивно понятным и удобным для пользователя.
Однако существует ряд проблем, которые необходимо решить, прежде чем мультимодальный поиск станет повсеместным. Одна из проблем заключается в необходимости надежных моделей встраивания, способных понимать семантическую сложность различных модальностей. Другая проблема заключается в необходимости масштабируемой инфраструктуры, способной обрабатывать огромные объемы данных, необходимые для мультимодального поиска.
В целом, я считаю, что мультимодальный поиск обладает потенциалом, способным революционизировать то, как мы ищем и потребляем информацию. Мне не терпится увидеть, как эта технология будет развиваться в ближайшие годы.