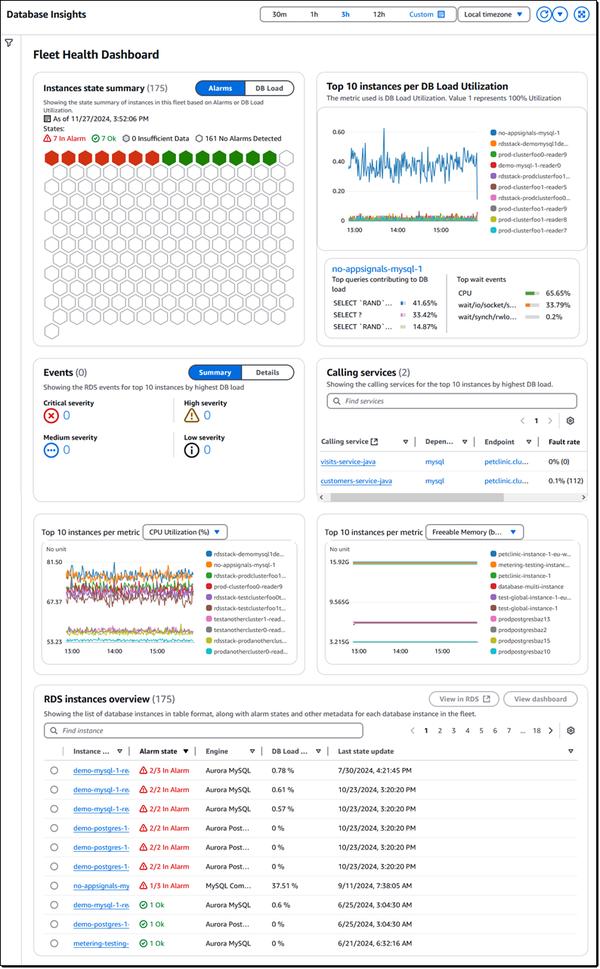
Google опубликовала пост в блоге о тонкой настройке больших языковых моделей, уделив особое внимание Gemma. В статье представлен обзор процесса от начала до конца, начиная с подготовки набора данных и заканчивая тонкой настройкой модели, настроенной по инструкциям.
Мне показалось особенно интересным то, как они подчеркнули важность подготовки данных и оптимизации гиперпараметров. Очевидно, что эти аспекты могут оказывать существенное влияние на производительность модели, и их необходимо тщательно учитывать.
Одна из проблем, с которой я часто сталкиваюсь в своей работе, — это обеспечение того, чтобы чат-боты понимали нюансы языка, справлялись со сложными диалогами и давали точные ответы. Подход, описанный в этом посте, кажется многообещающим решением этой проблемы.
Мне было бы интересно узнать больше о деталях процесса настройки гиперпараметров. Например, какие именно параметры были настроены и как были определены оптимальные значения? Более подробное обсуждение этого аспекта было бы очень полезным.
В целом, я нашел этот пост в блоге очень информативным, он дает полезный обзор тонкой настройки больших языковых моделей. Думаю, эта информация будет ценна для всех, кто хочет создавать чат-ботов или другие приложения, основанные на языке.