Amazon Bedrock анонсировала новые возможности оценки RAG и LLM-as-a-judge, упрощающие тестирование и улучшение генеративных ИИ-приложений. Базы знаний Amazon Bedrock теперь поддерживают оценку RAG, позволяя запускать автоматическую оценку базы знаний для оценки и оптимизации приложений Retrieval Augmented Generation (RAG). В процессе оценки используется большая языковая модель (LLM) для вычисления метрик. Это позволяет сравнивать различные конфигурации и настраивать параметры для достижения оптимальных результатов. Оценка модели Amazon Bedrock теперь включает LLM-as-a-judge, позволяя тестировать и оценивать другие модели с качеством, подобным человеческому, за долю стоимости и времени. Эти возможности обеспечивают быструю автоматизированную оценку ИИ-приложений, сокращая циклы обратной связи и ускоряя улучшения. Оценки учитывают такие критерии качества, как правильность, полезность и критерии ответственного ИИ, такие как отказ от ответа и вредность. Результаты предоставляют объяснения на естественном языке для каждой оценки, нормализованные от 0 до 1 для удобства интерпретации. Рубрики и подсказки судьи публикуются в документации для обеспечения прозрачности.
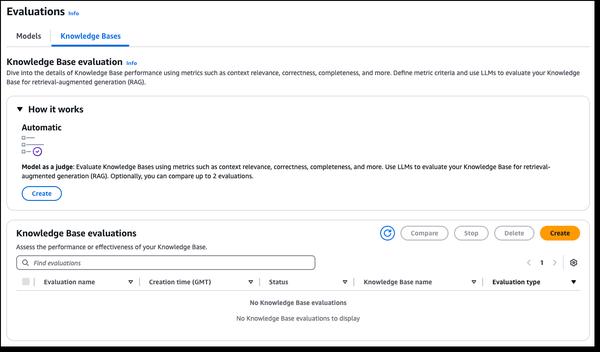
Новые возможности оценки RAG и LLM-as-a-judge в Amazon Bedrock
AWS